In der komplexen Welt von eingebetteten Systemen und Internet-of-Things-(IoT)-Architekturen ist Timing nicht lediglich eine Metrik; es ist eine grundlegende Einschränkung, die die Stabilität des Systems bestimmt. Wenn mehrere Threads oder Interrupts gleichzeitig versuchen, auf gemeinsam genutzte Ressourcen zuzugreifen, entsteht die Möglichkeit einer Race Condition. Diese Anleitung bietet eine technische Untersuchung, wie solche Synchronisationsprobleme mithilfe von Zeitverlaufsdiagrammen diagnostiziert werden können. Wir werden die Mechanik der gleichzeitigen Ausführung untersuchen, Signalübergänge analysieren und den genauen Moment identifizieren, in dem die Logik vom vorgesehenen Verhalten abweicht.
🧩 Verständnis der Konkurrenz in eingebetteten Systemen
IoT-Geräte arbeiten oft unter strengen Einschränkungen hinsichtlich Energieverbrauch und Verarbeitungsleistung. Um die Effizienz zu maximieren, implementieren Entwickler häufig gleichzeitige Prozesse. Das bedeutet, dass die zentrale Verarbeitungseinheit (CPU) mehrere Aufgaben, wie Sensormessungen, Netzwerkkommunikation und Stellaktorsteuerung, scheinbar gleichzeitig bearbeitet. Allerdings ist echte Parallelität bei Mikrocontrollern mit einem einzigen Kern selten. Stattdessen erzeugt der schnelle Kontextwechsel die Illusion von Gleichzeitigkeit.
- Gemeinsamer Speicher:Variablen, auf die sowohl eine Interrupt-Service-Routine (ISR) als auch die Haupt-Schleife zugreifen können.
- Hardware-Peripheriegeräte:Register, die für die UART-, SPI- oder I2C-Kommunikation verwendet werden.
- Zustandsmaschinen:Logik, die aufgrund externer Auslöser wechselt.
Wenn diese Elemente ohne geeignete Synchronisationsprimitiven interagieren, wird der Systemzustand nicht deterministisch. Eine Race Condition tritt auf, wenn das Ergebnis eines Prozesses von der relativen Zeitreihenfolge von Ereignissen abhängt, die nicht garantiert in einer bestimmten Reihenfolge eintreten.
📊 Die Rolle von Zeitverlaufsdiagrammen bei der Fehlersuche 🛠️
Ein Zeitverlaufsdiagramm ist eine visuelle Darstellung von Signalen über eine definierte Zeitachse. Im Kontext der Fehlersuche dient es als forensisches Werkzeug. Im Gegensatz zu einer statischen Codeüberprüfung erfasst ein Zeitverlaufsdiagramm das dynamische Verhalten der Interaktion zwischen Hardware und Software. Es ermöglicht Ingenieuren, Latenz, Jitter und überlappende Ausführungsintervalle zu erkennen.
Wichtige Komponenten eines Zeitverlaufsdiagramms
| Komponente | Beschreibung | Relevanz für Race Conditions |
|---|---|---|
| Zeitachse | Horizontale Linie, die die Dauer (ns, μs, ms) darstellt | Stellt die Reihenfolge der Ereignisse fest |
| Signalzeilen | Senkrechte Linien, die bestimmte Pins oder Variablen darstellen | Zeigt Zustände (high/low) oder Datenänderungen an |
| Übergänge | Kanten, an denen sich der Signalzustand ändert (anstiegend/abfallend) | Zeigt Auslösepunkte für Interrupts an |
| Verzögerungs-Marker | Verzögerungen zwischen Auslöser und Antwort | Deckt Verarbeitungsbottlenecks auf |
🏭 Fallstudien-Szenario: Intelligente Energiemessung
Betrachten Sie einen IoT-Energiemesser, der dazu konzipiert ist, Spannungs- und Stromimpulse zu messen. Das Gerät muss diese Impulse in nichtflüchtigem Speicher protokollieren, während es gleichzeitig ein Zusammenfassungspaket über einen zellulären Modul an ein Cloud-Gateway überträgt. Die Systemarchitektur beinhaltet eine Hauptanwendungs-Schleife und einen Hardware-Interrupt, der durch eine Überschreitung der Spannungsschwelle ausgelöst wird.
Systemvorgaben
- Mikrocontroller:32-Bit-ARM-Cortex-M4-basierter Prozessor
- Geteiltes Ressourcen:Eine 4-Byte-Zählervariable im RAM
- Interrupt-Quelle:Externer Spannungsvergleicher
- Aufgabe der Haupt-Schleife:Periodische Datensammlung und Übertragung
Die beabsichtigte Logik ist einfach: Wenn ein Spannungsschub auftritt, erhöht der Interrupt den Zähler. Die Haupt-Schleife liest den Zähler, überträgt den Wert und setzt ihn auf null zurück. Unter normaler Last funktioniert dies. Unter hoher Last tritt jedoch Datenkorruption auf.
📈 Analyse des Signalflusses
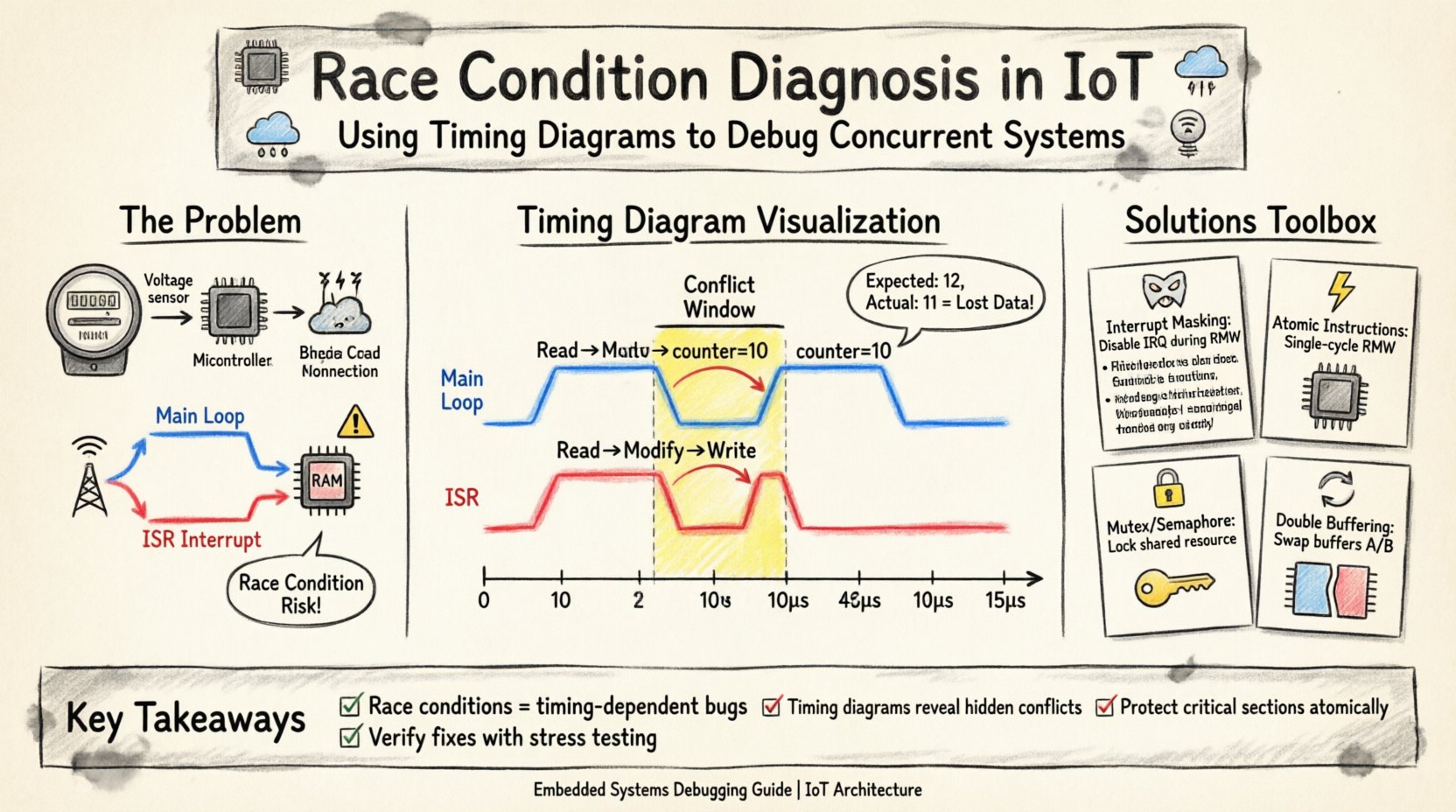
Um das Problem zu diagnostizieren, erstellen wir ein Zeitdiagramm, das sich auf die Interaktion zwischen der Interrupt-Service-Routine (ISR) und der Haupt-Schleife konzentriert. Das Diagramm visualisiert den Ablauf der CPU-Ausführung, den Signalzustand des geteilten Zählers und den Status der Peripherie-Datenleitung.
Phase 1: Der Lese-Ändere-Schreibe-Zyklus
Der Kern der Rennbedingung liegt im Lese-Ändere-Schreibe-(RMW)-Vorgang. Diese Operation ist auf vielen Architekturen nicht atomar. Sie umfasst drei verschiedene Schritte:
- Lesen:Die CPU holt den aktuellen Wert aus dem Speicher.
- Ändern:Die CPU addiert eins zum Registerwert.
- Schreiben:Die CPU speichert den neuen Wert zurück in den Speicher.
Wenn ein Interrupt zwischen Schritt 1 und Schritt 3 auftritt, ist die Integrität der Daten gefährdet. Betrachten wir nun die Darstellung dieses Ereignisses im Zeitdiagramm.
Zeitdiagramm-Darstellung
| Zeit (μs) | Haupt-Schleife | ISR | Wert des geteilten Zählers |
|---|---|---|---|
| 0 | Zähler lesen (Wert: 10) | Ruhezustand | 10 |
| 2 | Register enthält 10 | Interrupt ausgelöst | 10 |
| 5 | Ändern (10 + 1 = 11) | Zähler lesen (Wert: 10) | 10 |
| 8 | Interrupt ausstehend | Ändern (10 + 1 = 11) | 10 |
| 10 | Schreiben (11) | Schreiben (11) | 11 |
| 12 | Zähler zurücksetzen (0) | Zurück zum Interrupt | 0 |
| 15 | Ende des Zyklus | Zurück zur Hauptschleife | 0 |
Beachten Sie die Diskrepanz beim Endwert. Sowohl die Hauptschleife als auch der ISR lesen den Wert 10. Beide addieren eins, was zu einem Ergebnis von 11. Die Hauptschleife schreibt 11. Der ISR überschreibt dies mit 11. Das Endergebnis ist eine Zählung von 11, obwohl sie 12 betragen sollte. Der von der ISR erkannte Impuls wurde praktisch verloren, weil die Hauptschleife mitten in der Verarbeitung des vorherigen Zählerwerts war.
🔍 Identifizierung des Konfliktfensters
Das Zeitdiagramm macht das Konfliktfenster sichtbar. Dies ist der Zeitraum zwischen dem Lesen der Variablen durch die Hauptschleife und dem Schreiben des neuen Werts. Bei dieser spezifischen Architektur dauert der Zyklus etwa 8 Mikrosekunden. Die Interrupt-Latenz muss kürzer als dieses Fenster sein, damit die Rennbedingung auftreten kann.
Faktoren, die das Fenster beeinflussen
- Taktfrequenz: Höhere Frequenzen verringern die physikalische Dauer des RMW-Zyklus.
- Speicherlatenz:Wartezeiten in SRAM oder Flash können Lese-/Schreibzeiten verlängern.
- Compiler-Optimierungen:Inlining oder Registerzuweisung kann die Befehlsausführungszeit verändern.
- Interrupt-Priorität: Wenn die Interrupt-Priorität niedriger ist als ein kritischer Abschnitt in der Hauptschleife, kann die Rennbedingung maskiert werden.
Durch Messung der tatsächlichen Taktzyklen mit einem Logikanalysator oder einem on-chip Leistungsmonitor können Ingenieure das genaue Expositionsfenster berechnen. Diese Daten sind entscheidend dafür, zu bestimmen, ob eine einfache Softwarekorrektur möglich ist oder ob eine Hardware-Intervention erforderlich ist.
🛡️ Lösungsstrategien
Sobald die Rennbedingung über die Zeitanalyse bestätigt ist, sind spezifische architektonische Änderungen erforderlich. Ziel ist es sicherzustellen, dass der kritische Abschnitt (die RMW-Operation) atomar ausgeführt wird oder vor Unterbrechungen geschützt ist.
1. Interrupt-Maskierung
Der direkteste Ansatz besteht darin, während des kritischen Abschnitts Interrupts zu deaktivieren. Dadurch wird sichergestellt, dass kein ISR die Hauptschleife unterbrechen kann, während sie die gemeinsam genutzte Variable aktualisiert.
- Implementierung: Verwenden Sie Assembler-Befehle, um die Interrupt-Aktivierungsflag vor dem Lesen zu löschen und nach dem Schreiben wieder einzustellen.
- Vorteile:Garantiert Atomarität ohne komplexe Datenstrukturen.
- Nachteile: Erhöht die Interrupt-Latenz für alle anderen Peripheriegeräte. Hochprioritäre Interrupts können verzögert werden, was die Echtzeit-Leistung beeinträchtigt.
2. Atomare Befehle
Moderne Prozessoren bieten oft Hardware-Unterstützung für atomare Operationen. Diese Befehle führen die Lese-Ändere-Schreib-Sequenz in einem einzigen, unteilbaren Maschinenzyklus aus.
- Implementierung: Verwenden Sie Bibliotheks-Funktionen oder Intrinsics, die auf atomare Compare-and-Swap (CAS)- oder Fetch-and-Add-Befehle abgebildet sind.
- Vorteile: Minimaler Leistungsverlust; erfordert keine Deaktivierung globaler Interrupts.
- Nachteile: Hardware-Abhängigkeit; nicht auf allen älteren Mikrocontrollern verfügbar.
3. Software-Sperren (Mutex/Semaphore)
Für komplexere gemeinsam genutzte Ressourcen, wie z. B. einen Kommunikationspuffer, ist ein Sperremechanismus notwendig. Dies stellt sicher, dass nur ein Thread oder Prozess zur gleichen Zeit auf die Ressource zugreift.
- Implementierung: Ein Flag im Speicher, das anzeigt, dass die Ressource belegt ist. Die Haupt-Schleife prüft das Flag; der ISR prüft das Flag, bevor er auf die Ressource zugreift.
- Vorteile:Flexibel; ermöglicht die Priorisierung von Aufgaben.
- Nachteile:Führt zu Overhead bei Kontextwechseln und potenziellen Deadlocks, wenn nicht korrekt verwaltet.
4. Doppelte Pufferung
Bei Szenarien zur Datenübertragung kann die doppelte Pufferung die Notwendigkeit einer Synchronisation während der Schreibphase beseitigen. Die Haupt-Schleife schreibt in Puffer A, während der ISR aus Puffer B liest.
- Implementierung:Pflegen Sie zwei getrennte Speicherbereiche. Tauschen Sie die Zeiger aus, wenn ein vollständiger Block bereit ist.
- Vorteile:Verhindert Datenkorruption während der Übertragung; trennt Produktion und Verbrauch voneinander.
- Nachteile:Verdoppelt den Speicherverbrauch; erfordert sorgfältige Zeigerverwaltung.
🔄 Überprüfung und Testen
Nach der Anwendung einer Korrektur muss das Zeitdiagramm neu generiert werden, um die Lösung zu überprüfen. Ziel ist es, zu sehen, dass die Überlappung zwischen den kritischen Abschnitten der Haupt-Schleife und des ISR beseitigt wurde.
Testprotokoll
- Stresstest:Maximieren Sie die Interrupt-Häufigkeit und die Last der Haupt-Schleife, um ungünstigste Bedingungen zu erzeugen.
- Protokollanalyse:Vergleichen Sie den Zählerwert mit einer bekannten Referenz (z. B. externer Impulsgenerator).
- Signal-Aufnahme:Speichern Sie das Zeitdiagramm während des Stresstests, um die Abwesenheit des Konfliktfensters zu bestätigen.
Wenn das Zeitdiagramm zeigt, dass der ISR vollständig ausgeführt wird, bevor die Haupt-Schleife auf die Variable zugreift, oder dass die Variable während des Übergangs gesperrt ist, ist die Rennbedingung behoben.
📝 Häufige Fehler bei der Zeitverlaufsanalyse
Selbst mit einem Zeitdiagramm können Ingenieure die Daten falsch interpretieren. Mehrere häufige Fehler können zu falsch-negativen oder falsch-positiven Ergebnissen führen.
- Ignorieren von Jitter:Netzwerkverzögerung oder Taktschwankungen können dazu führen, dass Signalränder leicht verschoben werden. Ein statisches Diagramm kann diese Variabilität möglicherweise nicht erfassen.
- Übersehen von Leistungsmodi: Der CPU kann in Schlafzustände mit geringem Energieverbrauch wechseln, wodurch die Befehlsausführungszeit und die Zeitpunkte der Interrupt-Aufweckung verändert werden.
- Compiler-Variabilität: Unterschiedliche Optimierungsstufen (-O0 gegenüber -O2) können Befehle umordnen, wodurch die genaue Zeitgestaltung des kritischen Abschnitts verändert wird.
- Hardware-Latenz: Periphere Verzögerungen (z. B. Umwandlungszeit des ADC) werden oft in Software-Zeitdiagrammen nicht berücksichtigt, beeinflussen aber den Gesamtzustand des Systems.
🚀 Schlussfolgerung zur Diagnose
Die Diagnose einer Rennbedingung erfordert einen Wechsel von der statischen Codeanalyse zur dynamischen Signalbeobachtung. Das Zeitdiagramm liefert den notwendigen Kontext, um zu verstehen, wie Zeit mit der Logik in einer parallelen Umgebung interagiert. Durch die Abbildung des Ablaufs der Hauptschleife gegenüber dem Interrupt-Service-Routinen wird der genaue Zeitpunkt der Datenbeschädigung sichtbar.
Eine effektive Lösung erfordert die Auswahl der geeigneten Synchronisationsstrategie basierend auf den Hardware-Fähigkeiten und den Leistungsanforderungen. Unabhängig davon, ob über atomare Befehle, Interrupt-Maskierung oder eine architektonische Neugestaltung, bleibt das Ziel konstant: sicherzustellen, dass der gemeinsame Zustand unabhängig von der Ausführungszeit konsistent bleibt.
Da IoT-Geräte immer komplexer und vernetzter werden, verkleinert sich die Fehlermarge. Eine gründliche Zeitanalyse ist nicht nur ein Debugging-Schritt, sondern ein entscheidender Bestandteil des Entwicklungszyklus zuverlässiger eingebetteter Systeme.